Threshold configuration for EC2 instance and EBS volume
Site24x7 leverages various AWS service level APIs to auto-discover all running EC2 Instances and their attached EBS volumes from each Availability Zone. Once done, it creates an EC2 CloudWatch monitor for each instance in the Site24x7 console.
When an EC2 instance gets discovered (regular or Auto Scaling) and added as a monitor, a default threshold profile gets assigned to it. It's important to note that, this profile won't have any pre-populated thresholds. You can either edit the default profile or create yourself a new one.
To create a new threshold profile for your monitored EC2 instance and it attached Elastic Block Store (EBS) volume please follow the steps mentioned below. If you want to learn more about on how you can create alert contacts and customize alert settings, please visit our User and alert management page.
Overview
- Configure thresholds for EC2 CloudWatch monitor
- Configure thresholds for EBS volumes
- Configure threshold for integrated EC2 instance monitor
To Create a threshold profile for your EC2 CloudWatch monitor
- Click Admin > Configuration Profiles > Threshold and Availability.
- Click Add Threshold in Threshold and Availability screen.
- Specify the following details:
- Monitor Type: Select EC2 Instance Monitor from the drop down list.
- Display Name: Provide a label for identification purpose.
The performance metrics supported for your EC2 instance and EBS volume will be shown below. Configure values in the field provided, set up conditions (>, <, >=, <=) and assign alerting strategies on each attribute. The values you set up in each field will define the threshold. In the event of a threshold violation, the status of the EC2 instance CloudWatch monitor will change from Up to Trouble, triggering out an alert. Once you are done configuring threshold values, you can go ahead and save the profile. Once done, the profile will get listed in the Threshold and Availability page.
The following fields can be seen in the threshold profile
- Notify for auto scaling instance termination: Toggle to Yes to be notified when instances are created by auto scaling.
- Notify for auto scaling instance creation: Toggle to Yes to be notified when instances are terminated by auto scaling.
- Notify for agent failures: The Notify for Agent failures toggle box will only come into effect if you have deployed a Linux or a Windows agent on an already monitored EC2 instance.
- Notify for status check failures: Get immediately alerted when specific hardware or software issues start to plague your EC2 instance environment.
By default, alerting for EC2 status check failures — system status check and instance status check failures, both for regular and AutoScaling instances are enabled by default. Using the toggle box, you can also configure how you want to be notified in the event of a status check failure by moving the toggle to Critical, Trouble or Down. If you feel status checks are not necessary, then you can navigate to the threshold profile attached to your EC2 instance and set the toggle to NO, to turn it off. - Notify for Spot Instance Termination: By default, alert notifications for spot instance interruptions (terminations) will be disabled for all newly connected AWS accounts. If you feel alerts to notify spot fleet termination is necessary, you can navigate to the attached threshold profile and set the toggle to "Yes" to turn it on or create a threshold profile and bulk assign it to your monitored spot fleet.
- Notify for Reserved Instance Termination: By default, alerts for reserved instance termination (standard, convertible and scheduled type) are disabled. If you feel notifications are necessary, then navigate to the threshold profile of your monitored reserved instance and set the toggle to "Yes" to opt in. You can also create a new threshold profile and assign it in bulk.
- Notify for EMR instance Termination: By default, termination alerts for the EC2 instance groups powering you EMR cluster nodes—Master, Core, and Task nodes are muted. If you require email alert notifications, then navigate to the threshold profile for the monitored instance and set the toggle to Yes.
- Notify for Volume Status Check Failures: Choose Yes to get notified for any potential data inconsistencies in your EBS data volumes. Volume status checks are automated tests that are performed every 5 minutes by AWS. If the tests pass, the status of the volume is reported as "OK" if it fails, the status of the volume is impaired.
- Notify for GPU Connectivity Check Failure: Choose Yes to get notified for any potential connectivity issues between your EC2 Instance and GPU. GPU connectivity checks are automated tests that are performed every 5 minutes by AWS. If the tests pass, the status of the GPU connectivity is reported as "UP," if it fails, the status is reported as DOWN/TROUBLE/CRITICAL based on the defined attribute.
- Notify for GPU Health Check Failure: Choose Yes to get notified for any potential health check failure of your GPU that's connected to your EC2 Instance. GPU Health checks are automated tests that are performed every 5 minutes by AWS. If the tests pass, the GPU Health status is reported as "UP," if it fails, the status is reported as DOWN/TROUBLE/CRITICAL based on the defined attribute.
- Notify for Accelerator Health Check Failure: Choose Yes to get notified for any potential health check failure of your Elastic Inference Accelerator (EI Accelerator) that's connected to your EC2 Instance. EI Accelerator Health checks are automated tests that are performed every 5 minutes by AWS. If the tests pass, the EI Accelerator Health status is reported as "UP," if it fails, the status is reported as DOWN/TROUBLE/CRITICAL based on the defined attribute.
- Notify for Accelerator Connectivity Check Failure: Choose Yes to get notified for any potential connectivity issues between your EC2 Instance and Elastic Inference Accelerator (EI Accelerator). EI Accelerator connectivity checks are automated tests that are performed every 5 minutes by AWS. If the tests pass, the status of the EI Accelerator connectivity is reported as "UP," if it fails, the status is reported as DOWN/TROUBLE/CRITICAL based on the defined attribute.
- Suppress Agent Info Mail Alert: You can suppress agent information email alerts for integrated EC2 Instance monitors by enabling the Suppress Agent Info Mail Alert option. Agent information emails are typically sent to notify you about agent-related events. If you do not want to receive these emails, enable this option. Once enabled, Site24x7 will stop sending agent information email alerts for the selected monitor.
EC2 attributes
Monitor your Amazon EC2 instances on performance metrics like CPU utilization, disk I/O and network traffic. Site24x7 collects standard performance data for all your discovered EC2 instances. Once done, you can configure thresholds for each supported attribute using the Site24x7 UI.

Volume Threshold Configuration (EBS attributes)
Detect storage and I/O issues on your Elastic Block Store volumes. Set thresholds for performance counters like bandwidth, latency, and throughput for each attached EBS volume.
Attach a single global threshold profile for multiple EBS volumes
To configure thresholds for your Elastic Block Store (EBS) volume access the EC2 instance threshold profile (This houses all of this EBS attributes). You can either edit the default threshold profile assigned to your EC2 instance or you can create a new threshold profile and bulk assign it to all monitored EC2 instances. If you have attached multiple EBS volumes on the same EC2 instance, then the thresholds configured for the volume attributes will apply to all of them.
Configure individual thresholds for each attached EBS volume.
If you have attached multiple EBS volumes for increased storage capacity or increased I/O bandwidth, say for example you might be running a volume primarily as a root volume and have added two separate volumes to handle database and storage workloads, then you probably need to configure individual thresholds for each EBS volume. For such a case you can access the Volume tab for the said EC2 instance monitor, to set individual threshold profiles for each volume.


Threshold Configuration profile for an integrated EC2 instance monitor
An integrated EC2 instance monitor will come into existence when a user deploys an agent (Linux or Windows ) on an already monitored EC2 instance (monitored via our CloudWatch integration). This type of monitor will have two threshold profiles associated with it. One pertaining to the basic instance level CloudWatch metrics and an other pertaining to system metrics.
To configure thresholds, navigate to the edit section of the Integrated EC2 instance monitor page by following the below mentioned steps:
- In the left navigation pane of the console, choose AWS and choose the monitored AWS account.
- On the menu dropdown, choose EC2 instance. Choose the integrated EC2 instance monitor for which you want to configure thresholds.
- Click on the hamburger icon
 and choose Edit.
and choose Edit. - In the edit page under the Configuration Profiles section you will find that there are two threshold profile fields.
The Threshold Availability profile, will contain the standard EC2 performance counters associated with CloudWatch. Here, you can also configure whether you want to be alerted in the event of agent failure. This notification can either be configured to trouble or down as per your discretion.

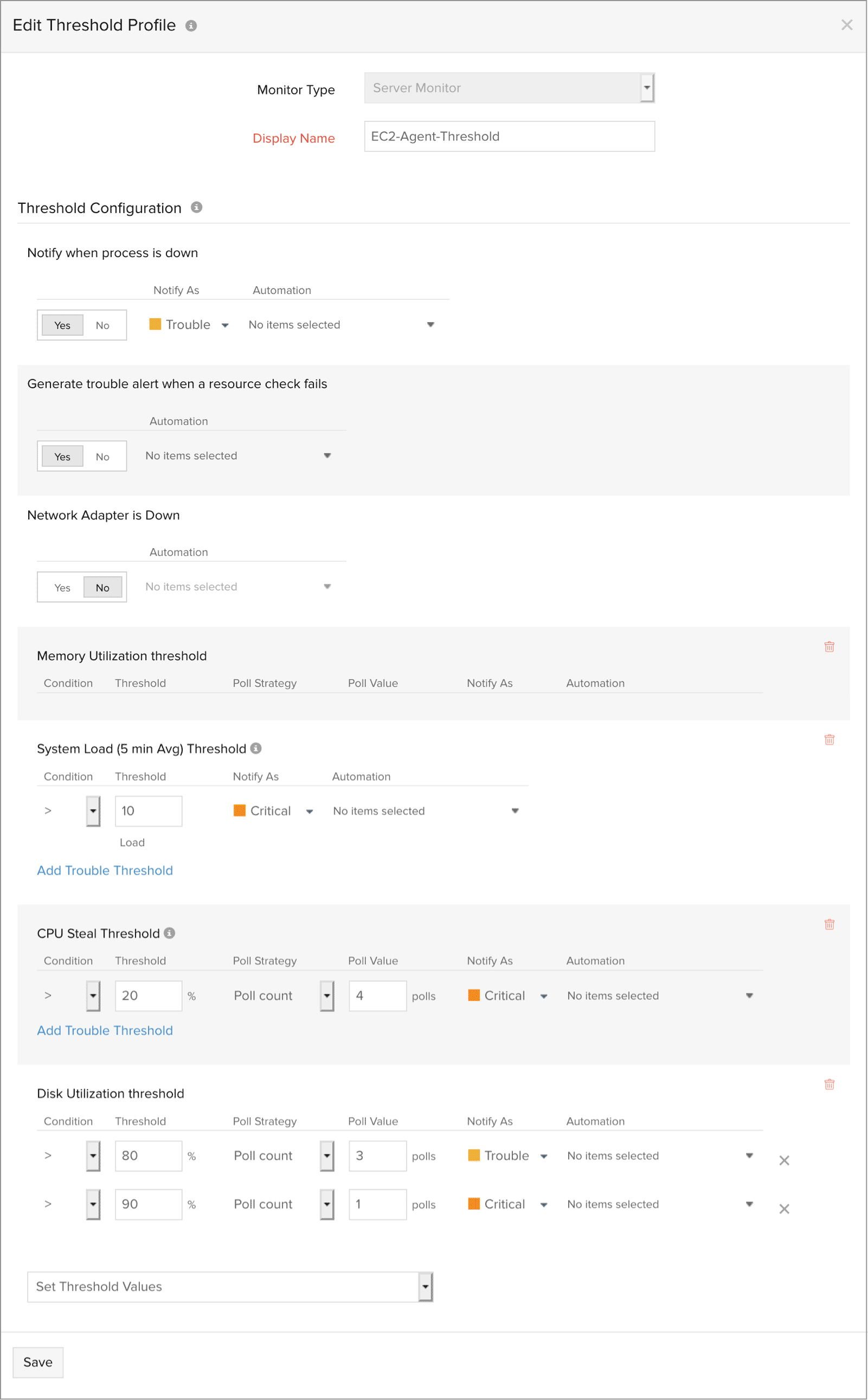
You can choose to be notified of your auto scaling instance is terminated. Choose 'Yes' for the option "Notify for Auto Scaling Instance Termination". The monitor will be suspended and an email alert will be sent to you, notifying you of the same.
Advanced Threshold Settings
You can also validate you threshold breach by configuring conditions and setting up alert strategies. For example, lets consider a scenario where you want to get alerted when your instance CPU utilization exceeds 95%. However, it is highly possible that a spike in network traffic can trigger an temporary increase in CPU, possibly exceeding 95%. For such a short term effect, you don't need to get alerted at the onset, may be the network load can comb back down, reducing your CPU utilization. For such a scenario you can configure an alerting strategy such as poll count or average duration to validate the CPU spike and to check whether it was permanent or short lived.
Advanced Threshold Settings (Strategy):
Poll count serves as the default strategy to validate the threshold breach. You can validate threshold breach by applying multiple conditions (=,>, <, >=, <=) on your specified threshold strategy. The monitor’s status changes to ”Trouble” when the condition applied to any of the below threshold strategies hold true:
- Threshold condition validated during the poll count (number of polls): Monitor’s status changes to trouble when the condition applied to the threshold value is continuously validated for the specified “Poll count”.
- Average value during poll count (number of polls): Monitor’s status changes to trouble, when the average of the attribute values, for the number of polls configured, continuously justifies the condition applied on the threshold value.
- Condition validated during time duration (in minutes): When the specified condition applied on the threshold value is continuously validated, for all the polls, during the time duration configured, monitor’s status changes to trouble.
- Average value during time duration (in minutes): Monitor’s status changes to trouble, when the average of the attribute values, for the time duration configured, continuously justifies the condition applied on the threshold value.
Multiple poll check strategy will not be applied by default. During the conditions where no strategy could be applied, the threshold breach will be validated for a single poll alone.
To make sure the condition applied on the strategy “Strategy-3: Time duration or Strategy-4: Average value during time duration” for threshold breach detection works as intended, you must ensure that you specify a time duration which is at least twice the applied check frequency for that monitor.