How Agentic AI speeds up troubleshooting application issues

Rizzy works nights for ZylkerXchange, Zylker’s foreign currency exchange app. He lives on the city’s outskirts, where the air is clean and quiet, and the night shift suited that life. Most nights, nothing happened. Some nights, everything did.
Before: Alone with the alerts, and alone with the noise
For two years, Rizzy’s shift followed the same pattern. An alert fired, then usually three or four more right behind it, all pointing at different symptoms of the same root problem. Roughly 74% of the alerts IT and CloudOps teams get in a day are noise: Duplicates, false positives, and low-priority triggers that don’t require a human intervention. Rizzy didn’t know that number. He just knew that before he could fix anything, he had to figure out which of the alerts in front of him was the real one.
Once he found it, the actual investigation started: Opening application traces, pulling up the dependency map by hand, checking server metric graphs around the time the trace started, then cross-referencing all of it against the logs separately, because none of those views talked to each other. If the cause wasn’t obvious in twenty minutes, he escalated and waited for someone in another time zone to wake up.
This wasn’t unique to Zylker. According to a recent survey, 40% of SREs respond to more than five incidents in a thirty-day window, and 23% handle six to 10. What made the load heavier wasn’t the volume. It was doing all of that alone, alert by alert, tool by tool.
The night ZylkerXchange went down
The alert that changed things looked routine at first, except it wasn’t six alerts. It was one.
ZylkerXchange’s currency exchange transaction started failing mid-conversion, and the application dependency map showed it as a single red node, not a flood of separate complaints from every component downstream of it. Behind that node, the correlation engine had already done the unglamorous part of identifying the issues: A spike in database latency, a rise in error rates on the rate-provider API call, and a memory pressure event on the container running it, three signals that on their own meant nothing. However, they stitched into one problem because they shared the same root cause and time window. That stitching is the exact thing Rizzy used to do by hand, with three browser tabs open and no one else online to help.
He asked Zia directly for the alerts and the RCA report, the same late-night, no-team-available scenario Site24x7’s own documentation describes, and Zia answered in plain language: The rate-provider call was timing out and cascading into every exchange request behind it. The distributed trace backed it up, showing the exact failing call instead of a vague something downstream is slow . Rizzy didn’t open a single dashboard to get there.

The stakes were real. For 90% of midsize and large enterprises, an hour of downtime now costs more than $300,000. With the cause confirmed, a guard-railed AI Agent flagged the failing dependency and executed the approved remediation, task-driven automation that moves from analysis to action without a human typing the command. Eleven minutes after the first alert, ZylkerXchange was back.
The agent Rizzy built himself
The rate-provider call failed twice more over the following month, same pattern, same fix. The third time, Rizzy didn’t wait for the platform default; he built his own.
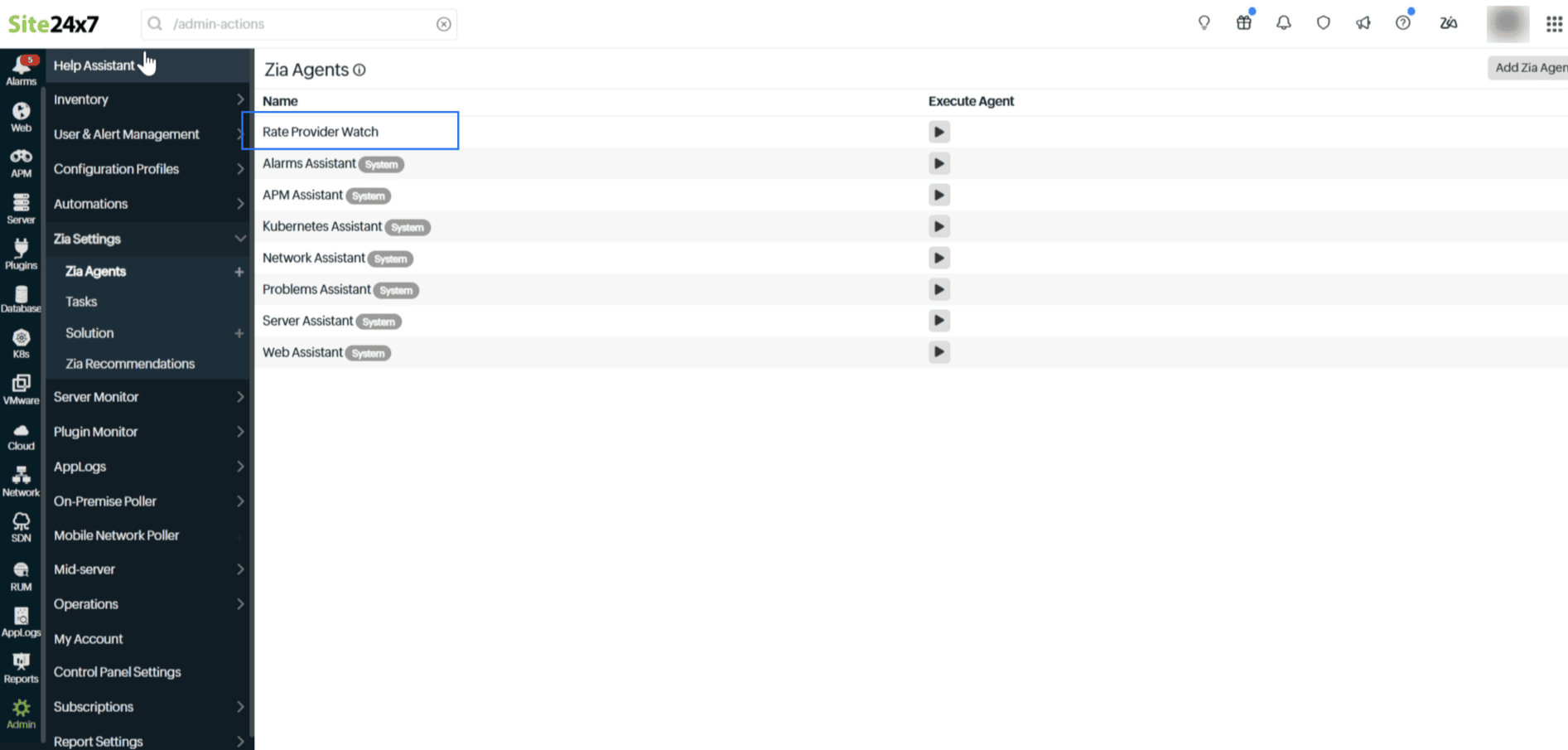
Zia Agents can be configured as user-defined, scoped to a specific module and monitor type, and linked to a solution containing your own validated queries and instructions. Rizzy named his agent Rate Provider Watch , described exactly what it should catch, and attached the remediation steps that he had run three times from memory. The next time that pattern showed up, it wasn’t the platform’s general-purpose response handling it. It was something Rizzy had personally taught the system to recognize.
What was already running, before any agent got involved
Not every night had a P1. Most nights, the only thing working was a layer Rizzy never had to invoke at all.
Site24x7’s anomaly detection runs continuously in the background, using statistical modeling to build a dynamic baseline instead of a fixed threshold, so it catches a real deviation without Rizzy having to set a hardcoded number that would either fire constantly or miss a slow drift toward failure. Each anomaly gets scored Confirmed or Likely based on severity and dependencies, and a separate forecasting model flags resource trends before they become incidents. On the rare night something did go down outside ZylkerXchange’s core flow, an RCA report triggered automatically, capturing the top resource processes at the moment of failure, before Rizzy had even opened his laptop. None of that needed an agent. It was just running.
After: Fewer fires left to fight
Rizzy didn’t get less busy. He just wasn't alone, and the hour each incident used to cost him in investigation came back as time he could spend before the next one started.
He used it to tighten ZylkerXchange’s SLOs: Shaving response-time thresholds, and closing gaps in the dependency map before they became the next alert. His shift stopped being measured by how many fires he could put out and started being measured by how few were left to find.
At the end of the quarter, Zylker named him Best Employee. Not for outlasting more chaos, but for there being less of it left for anyone to outlast.
What most AIOps stories leave out
Industry-wide, AI hasn’t fixed this yet. Rizzy’s result is one named, sourced outcome at one company, not proof the category has solved itself.
Also, faster RCA doesn’t erase the page. Research on on-call work links it to disrupted sleep and reduced next-day performance, regardless of how fast the fix comes. Rizzy still gets the late-night page. What changed is what happened in the fifteen minutes after.
The shift that changed
The incident was never the real cost. The wait for someone else’s morning was.
See what Ask Zia and Zia Agents would catch on your own night shift.
FAQs
1. What is agentic AI in IT operations? Agentic AI is AI that takes scoped action toward a goal, not just surfaces insights. In IT operations, it moves AIOps from passive detection to guided remediation. Unlike a chatbot, it can carry out tasks, not only answer questions.
2. How does agentic AI speed up troubleshooting for application issues? Agentic AI compresses the slow part of troubleshooting by finding the real cause among the noise. It correlates related signals into one root cause, explains it in plain language, and can trigger an approved fix. That removes the manual cross-referencing of traces, maps, metrics, and logs.
3. Can I create a custom Zia Agent for a recurring issue? Yes. You can configure a user-defined Zia Agent scoped to a module and monitor type, with your own instructions and a linked solution holding validated runbooks. The next time that pattern appears, the agent follows your steps instead of a generic default.
4.How does agentic AI reduce mean time to recovery (MTTR)? Agentic AI cuts the investigation phase that drives most of MTTR. It correlates signals into one root cause, explains the failure in plain language, and can run an approved remediation without manual steps. The result is less time spent diagnosing and more incidents resolved before they escalate.
5.How is agentic AI different from traditional alerting and AIOps? Traditional alerting fires a separate notification for every symptom and leaves the diagnosis to you. Earlier AIOps added correlation and anomaly detection but still stopped at insights. Agentic AI goes one step further, acting on those insights to investigate and run an approved fix.