I was wondering if it's possible to setup a server monitor so that it will capture performance data about all running processes and services dynamically? I know I can manually add services and processes that I want to alert against. What I want to be able to do is see what process or service is historically causing a high CPU usage percentage even if the service/process happens to be one that is NOT already added to the monitored services list.
Like (1)
Reply
Replies (1)
by Gibu Mathew
That is a nice use case.
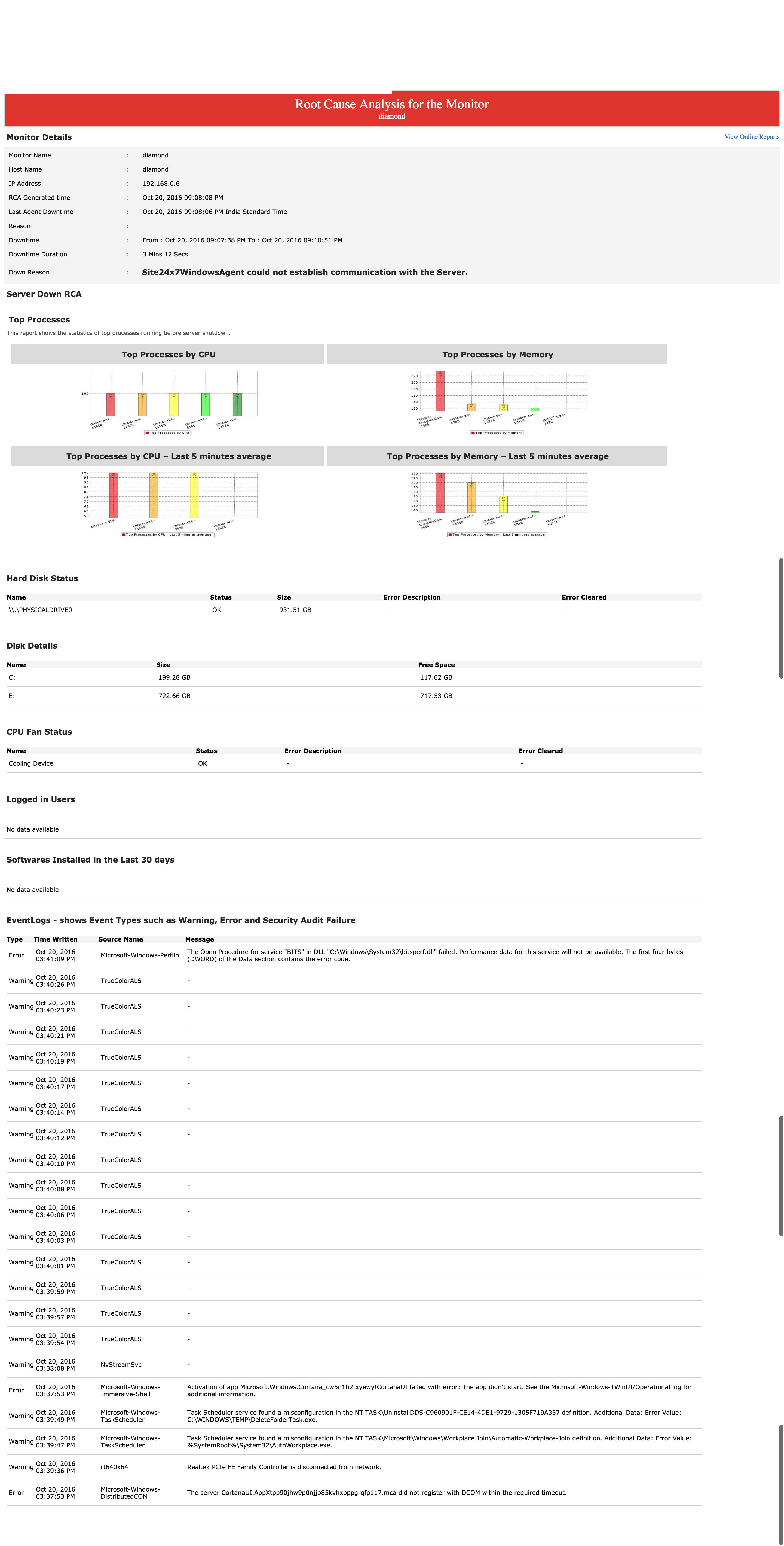
BTW I hope you are aware that we provide a snapshot of top processes that were running when a threshold is violated or when a server goes down. We send this RCA as an email to the configured user.
I have attached a screenshot of that RCA View here.
We would like to hear any comments you have around that to see how we can make improvements to satisfy your use case too.
In the meantime we will think how we can automagically figure out the top 10 processes that take high CPU and memory across servers over say a fixed unit of time (like every hour).
BTW I hope you are aware that we provide a snapshot of top processes that were running when a threshold is violated or when a server goes down. We send this RCA as an email to the configured user.
I have attached a screenshot of that RCA View here.
We would like to hear any comments you have around that to see how we can make improvements to satisfy your use case too.
In the meantime we will think how we can automagically figure out the top 10 processes that take high CPU and memory across servers over say a fixed unit of time (like every hour).
Like (0)
Reply