Check the health and availability of your Linux servers for optimal performance with Site24x7's Linux monitoring tool.
Most production servers nowadays run on Linux—be it Debian, Ubuntu, or Centos—thanks to the operating system’s versatility and the fact that it’s free to use. Linux has a wide range of tools to support, manage, monitor, and deploy software applications.
Services and features added to the product application can consume considerable memory. Optimizing memory for Linux servers not only makes applications run smoother and faster, it also reduces the risk of data loss and server crashes. In this article, we will walk through a few ways to optimize memory in Linux.
To optimize memory for Linux machines, we first need to understand how memory works in Linux. We’ll start with some memory terms, discuss how Linux handles memory, and then learn how to troubleshoot and prevent memory issues.
The total amount of memory that one machine can contain is based on the operating system’s architecture. For example, a 32-bit architecture operating system can only support 4 GB of memory while a 64-bit one can support around 128 GB (theoretically, it could support up to 16 EB if hardware capabilities improve).
The entire memory in Linux is called virtual memory—it includes physical memory (often called RAM) and swap space. The physical memory of a system cannot be increased unless we add more RAM. However, the virtual memory can be increased by using swap space from the hard disk.
RAM determines whether your machine can handle high memory-consuming processes. For example, we’ll need at least 1 GB of RAM for 1,000 assets using MongoDB in a production server. To ensure satisfactory performance of the server, the physical memory must exceed what the database needs—otherwise MongoDB will start using swap memory instead, reducing system performance. The reason behind this is that physical memory is accessible in nanoseconds but swap memory only within milliseconds.
Typically, physical memory takes care of storing data for all processes in the computer. But what happens when the physical memory is full? This is when the swap memory comes into play.
When the system is full, inactive pages in memory will be moved to swap memory, consisting of a swap partition, a swap file, or both. A swap partition is a disk partition, whereas a swap file is a file system. Using one or the other boils down to preference, as they’re both valid options.
Disk memory, or hard drive memory, is often bigger than physical memory. While computing, the data for currently running tasks are stored in RAM; if the computer loses power, that data is gone. This is why it’s important to frequently save your work —disk memory saves persistent data.
Below is a flow diagram demonstrating how data is processed in Linux.
Data from the user, computer processes, and HDD is sent to RAM. If needed, RAM will store and send it back to the user or HDD. If the data needs to be persistent, RAM will send it to the CPU.
To detect memory problems and optimize memory in Linux, we’ll need one of several tools.
Hardware problems can directly affect memory optimization. Let’s say, for example, that your website is running slow and a local program has slowed to a crawl. To see whether this is due to a RAM problem, you’ll need to remove RAM modules and test them to determine which one is at fault.
dmidecode can help retrieve system hardware information while checking for hardware problems. The dmidecode tool helps display your system management BIOS in the table content.
For example, run
dmidecode
This will show the below information about memory.
Not having enough free space to run tasks is one of the most common reasons behind a slow computer. To check for available free space in your machine, you can use the free command.
free -g
This will show the free space of memory in GB.
 Fig. 3: Information about free memory space in the machine
Fig. 3: Information about free memory space in the machine
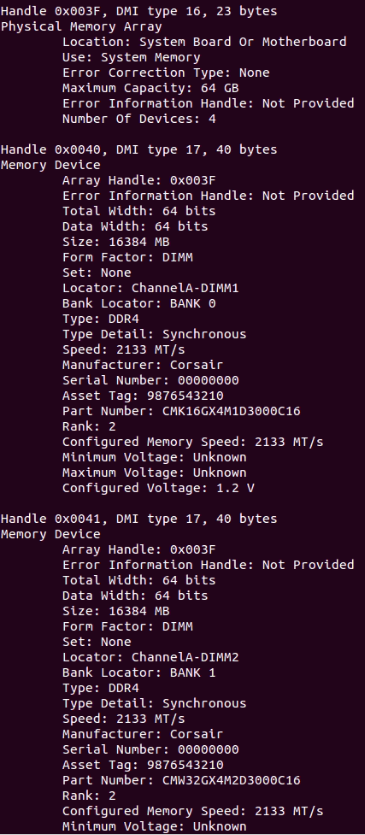 Fig. 2: dmidecode displays information about system hardware
Fig. 2: dmidecode displays information about system hardware
There are multiple command line tools to check CPU usage and memory, including htop, vmstat, and ps.
htop displays real-time information about CPU processes.
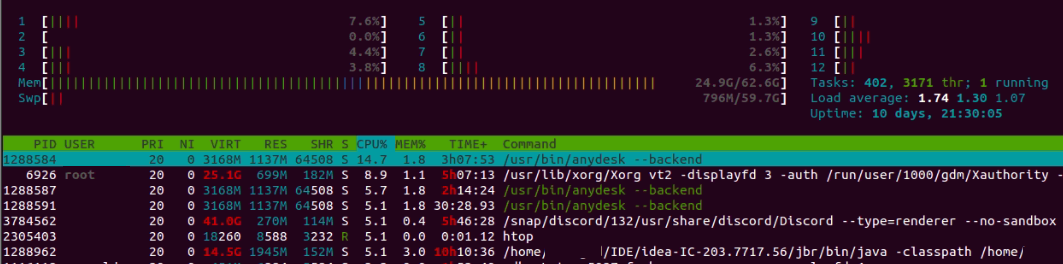 Fig. 4: htop showing real-time information about current running processes
Fig. 4: htop showing real-time information about current running processes
vmstat shows information about CPU, memory, system processes, paging, interrupts, and CPU scheduling.
For example, run
vmstat -a -S M
This will show information about memory in MB.
 Fig. 5: Memory information in MB
Fig. 5: Memory information in MB
ps gives us information about running processes in Linux.
For example, ps -aux shows all running processes.
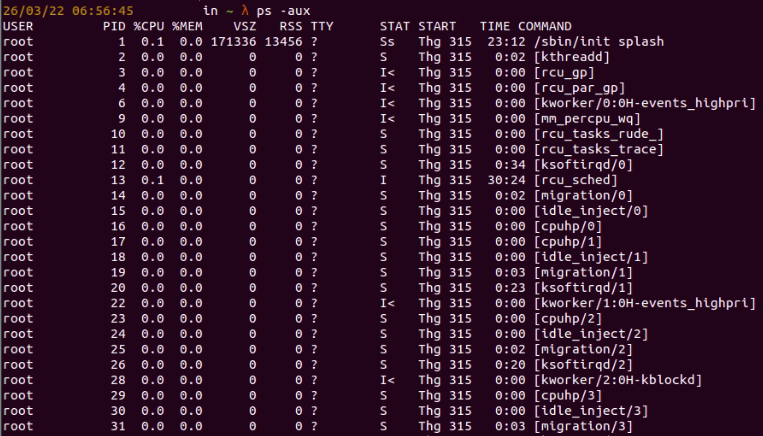 Fig. 5: Memory information in MB
Fig. 5: Memory information in MB
A Linux server can consume a considerable amount of memory for various reasons. For quick and effective troubleshooting, first we need to rule out the most likely reasons.
There are several applications implemented using Java, and their incorrect implementation or configuration can lead to high memory usage in the server. The two most common causes are wrong configuration in caching and session caching anti-pattern.
Caching is a common way to achieve high performance for applications but when applied incorrectly, it can end up hurting system performance instead. The wrong configuration could make the cache grow too quickly, leaving less memory for other processes running in the system.
Session caching is often used when storing the intermediate state of the application. It allows developers to store users per session and makes it easy to save or get data object value. However, developers tend to forget to clean up session caching data afterward.
When working with databases in Java, hibernate session is commonly used for creating connections and managing the session between the server and the database. But there’s an error that frequently occurs when developers work with hibernate sessions. Instead of being isolated for thread safety, the hibernate session is included in the same HTTP session. This makes the application store more states than necessary, and with only a few users, memory usage greatly increases.
When discussing high memory–consuming processes, we must mention databases. With many reads and writes to the database while the application handles user requests, our database can consume considerable memory.
Take a MySQL database as reference: To achieve high performance, it applies a buffering mechanism for caching and indexing data. If we configure the database to use maximum memory when we have several requests to the database, the memory in our Linux server will soon be overwhelmed.
When using Amazon EC2, we should pay attention to the machine’s configuration. There have been reports of malware exploiting vulnerable Amazon EC2 instances for cryptomining. When this occurs, we’ll often see a large uptick in memory usage and the system freezing.
Memory overcommit is the term used to describe what happens when we allow the application to use more virtual memory than the physical memory can serve. On the one hand, this helps the system avoid underutilizing RAM. On the other hand, if the system is allowed to keep giving out virtual memory to programs uncontrolled, it will crash when there’s no physical memory left.
Optimizing memory in Linux is a complex undertaking, and fixing an overloaded memory requires significant effort. Here are some best practices that can help prevent memory issues from occurring.
Create a swap partition in your server; it can be used as virtual memory for your server. In a worst-case scenario where the physical memory is full, the memory belonging to inactive processes will be moved to swap space, allowing the vital active processes that need memory to continue.
A ramdisk is used for application caching or work areas. It’s a volatile storage space that is defined within the RAM. Using ramdisk increases file-processing performance: Compared to solid state drives (SSD), ramdisk is over 50 times faster. Creating a ramdisk is beneficial when you have an application server that requires significant amounts of hardware resources to run.
To minimize the risk of hacking, only open the ports you need at a given time. In addition, limit access ports via a virtual private network.
If you encounter a malware attack, such as a cryptomining attempt, double-check both inbound and outbound ports—and, again, only open the ports you need. Next, you need to remove crontab from your instances, as the malware created the crontab to trigger the mining jobs.
To conserve memory, stop services or containers not in use. For example, when deploying applications to a QA or development environment using Docker, you can create a Docker image, volume and run Docker container for testing purposes. These can be cleaned up after testing is complete.
Optimizing memory for your Linux device will save valuable memory from storing data in unnecessary processes or caching unused data. Your applications will run smoother, reducing the risk of losing data or crashing the server. This, in turn, can save the entire team considerable frustration, not to mention time and money.
Site24x7 tracks physical memory, swap memory, and cached/buffered memory, providing a complete picture of your Linux server's memory utilization.
Yes, Site24x7's process monitoring automatically identifies the top memory-consuming processes, helping you pinpoint memory leaks or resource-hungry applications.
Site24x7 supports dynamic thresholds for memory metrics including swap usage. You can also configure custom thresholds for swap utilization and page faults to receive proactive alerts before memory constraints impact your application's performance.
