Azure Cosmos DB is a globally distributed, multi-model database service that offers scalable throughput and storage. Partitioning enables this scalability and allows for highly efficient data management.
However, you need an effective strategy to improve data distribution across partitions. It’s important to select partition key properties carefully for distributing and organizing data across multiple physical partitions in a database. Otherwise, you might end up with unbalanced loads.
This article explores partitioning in Azure Cosmos DB, focusing on selecting partition keys, handling unbalanced loads, and managing data distribution.
Partitioning in Azure Cosmos DB is both an art and a science—a delicate balance of understanding the data, predicting usage patterns, and making strategic decisions about data distribution. The goal is to distribute data and requests evenly across all partitions for optimal performance.
Azure Cosmos DB uses horizontal partitioning to scale out data. It then distributes the data across many partitions, each served by a different server. By sharing the load across multiple servers, horizontal partitioning helps the database provide high throughput and storage.
The diagram below illustrates horizontal partitioning in a server monitoring system context. In this example, server event data is divided into shards based on the EventType key. Each shard holds the data for a specific type of event (for example, Error, Info, and Warning). In this case, partitioning organizes the events categorically based on the type of event.
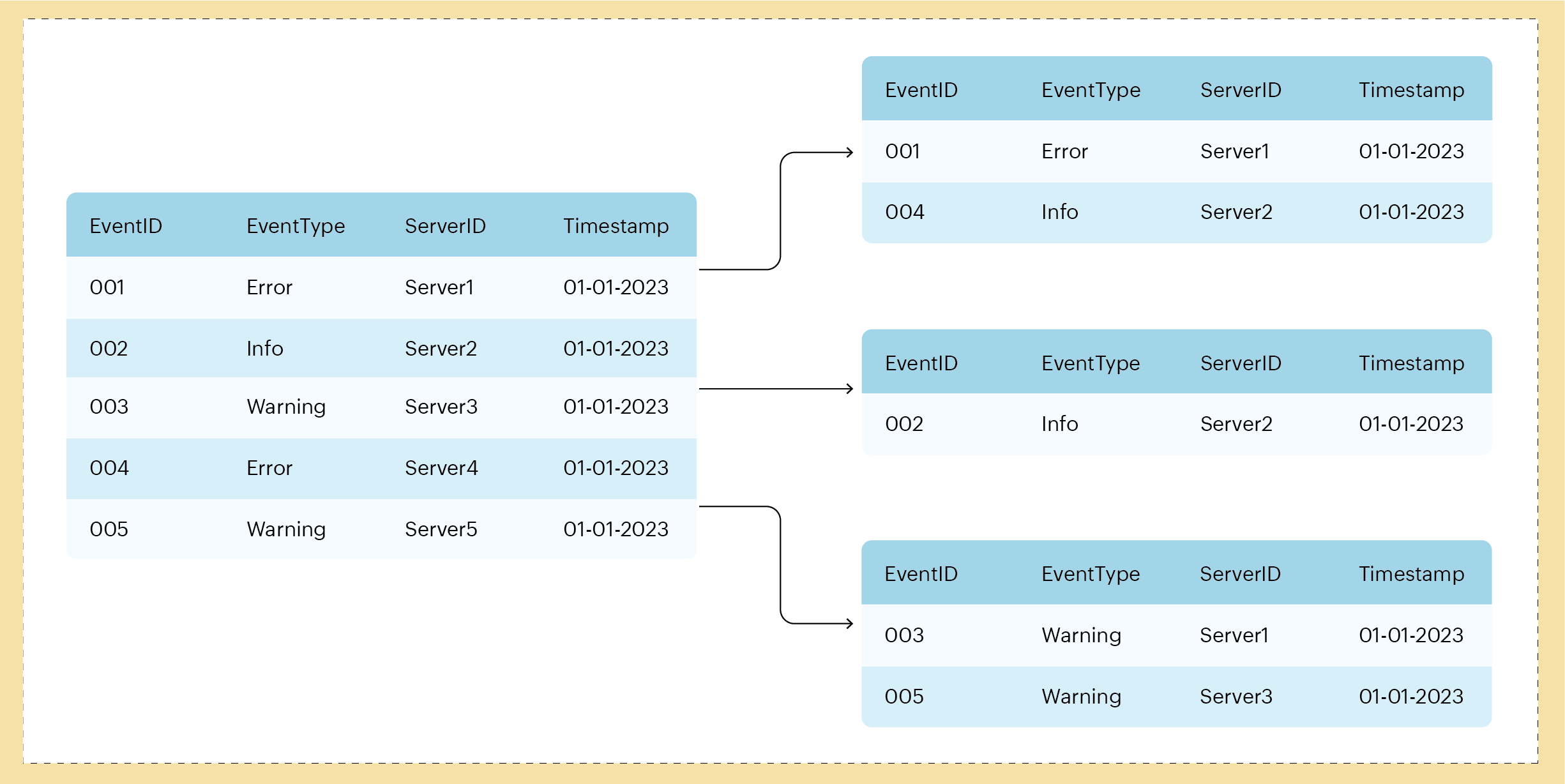 Fig. 1: Horizontally partitioning data based on a partition key
Fig. 1: Horizontally partitioning data based on a partition key
The most important element of the horizontal partitioning strategy is the partition key—a property associated with all the items stored in the container. You define the partition key when creating a container in Azure Cosmos DB, and the database then uses this key’s value to decide how to distribute the items. Ideally, the items are distributed evenly across multiple partitions so that every partition has approximately the same amount of data and shares the workload fairly. Balancing the load in this way enhances the performance of queries and transactions.
Choosing your partition key requires a deep understanding of your data and how your application will interact . This is the “art” portion of the process. An inadequate partition key can lead to imbalanced data distribution and hot partitions, which are partitions with high volumes of data or requests.
Your choice of partition key also affects your operation costs. Azure Cosmos DB uses a consumption-based pricing model based on request units (RUs), with every operation—reading, writing, and querying data—consuming a certain number of RUs. Operations on a single partition consume fewer RUs than cross-partition operations, which is why a well-chosen partition key can reduce costs.
The importance of selecting a partition key is often underestimated—it’s one of the pivotal decisions when setting up a Cosmos DB. A partition key is a guiding compass, directing how the data journey unfolds within the database. Its role is to decide where and how data is placed. Choosing the right partition key is a delicate balancing act that requires foresight and a solid understanding of your data usage patterns.
Let’s examine some issues that can arise when selecting partition keys. In this section, we’re focusing on server monitoring systems paired with Cosmos DB—specifically, Site24x7, an all-in-one monitoring solution.
Imbalanced data distribution can occur due to improper partition key selection, overloading some partitions while others remain underused. You risk choosing the wrong partition key if you fail to consider data access patterns, workload distribution, and the growth potential of the system, leading to imbalanced data and operational load. For example, if you use ServerID as the partition key and a particular server creates a notably higher amount of events or logs, it could cause all data entries for that server to go to one partition.
Another challenge is workload skew, where operations are unequally distributed across partitions. For example, if Time is used as the partition key in a server monitoring system, all data entries will be distributed according to the time they were received or created.
During peak hours, a surge in activity means that the server monitoring system generates a larger volume of data, which is then directed to the partitions corresponding to those specific times. Those partitions can become overloaded and suffer performance degradation. Conversely, underutilized partitions don’t leverage their capacity efficiently during off-peak hours when server activities are lower, resulting in wasted resources.
When data and workloads are unevenly distributed, the system is less scalable, so scalability depends on choosing the right partition key.
For example, you might choose EventType as the partition key when the system’s queries are often event-centric, meaning they require fetching or analyzing data based on the type of event. Say a server monitoring system wants to retrieve all error, warning, or information logs quickly. Having EventType as the partition key puts all events of the same type into the same partition., eliminating the need to query multiple partitions.
However, there’s a potential drawback to this approach. If the distribution of event types is not evenly balanced, it can lead to uneven data distribution.
When one partition in a distributed system receives many more read and write requests than others, it’s called a hot partition. This imbalance can create a performance bottleneck, causing latency issues and impacting system performance.
For an all-in-one server monitoring system to achieve optimal performance, it needs an even workload distribution across all partitions. A server monitoring system is crucial in overseeing various metrics related to the health and performance of servers, such as CPU usage, memory consumption, disk I/O, and more. Given the high volumes of data it processes and the real-time nature of the insights it provides, optimal performance is a necessity. Using MetricType as the partition key can lead to hot partitions during anomalous system events when a metric, like CPU use or Disk I/O, suddenly spikes.
To avoid this issue, use a composite partition key—in this example, by combining MetricType and EventTime. With this dual-key setup, you write data related to a certain metric type to a specific partition, spreading the workload more equitably. This strategy helps you maintain a balanced workload distribution across the system.
Data distribution in Cosmos DB occurs at two levels: global distribution and partitioning. Global distribution replicates data across regions, ensuring reduced latency, increased availability, and business continuity. Partitioning further divides data into partitions within each region, enabling horizontal scaling while maintaining performance.
However, if data clusters around a few partition keys, issues arise.
Inefficient data distribution increases costs, as hot partitions consume excessive RUs. Reduced availability is a risk if you don’t adequately distribute data and replicate it across regions, impacting resilience during regional outages. Workload skew and underutilization can also lead to wasted resources.
To avoid these issues, you should try to ensure even data distribution, avoid hot partitions, and optimize resource utilization in Cosmos DB. These strategies allow you to maintain optimal performance, scalability, availability, and cost-efficiency within your database.
Undoubtedly, the heart of managing data distribution is an effective partitioning strategy. This task is multifaceted, encompassing the wise choice of a partition key, meticulous observation to ward off instances of hot partitions, and the perpetuation of a methodical approach to data dispersion.
The journey to the ideal partition key is one of seeking equilibrium: The goal is to navigate the waters of workload distribution so smoothly that hot partitions become a concern of the past.
Keys should have high cardinality, with numerous unique values, allowing for a broad distribution of data and requests across partitions. Align the partition key with your query and transaction patterns—often, a property frequently included in queries makes a suitable partition key.
Monitor partition-level throughput using the metrics Cosmos DB provides to prevent hot partitions. Throughput, storage, availability, latency, and the rate of throttled requests are all crucial metrics to monitor when identifying and preventing hot partitions in Cosmos DB. If you identify a hot partition, consider adjusting the partition key to a property with a more even distribution. You should also implement rate limiting to prevent any single partition from being overwhelmed with requests.
Managing data distribution involves enabling multi-region writes for uniform data distribution and availability across all regions. Regularly review and adjust your partition strategy as your application evolves to accommodate data growth or changing usage patterns. Use features like Cosmos DB’s Time to Live (TTL) to manage storage costs and partition data volume. TTL automatically purges items after a defined period.
Following these best practices can enhance your data distribution management in Cosmos DB, help you circumvent common partition issues, and improve performance.
This article discussed the importance of effective data distribution and efficient partitioning in Azure Cosmos DB.
First, you explored the challenges arising from poor data distribution, such as hot partitions and capacity issues, and how they can impact the performance and scalability of your Cosmos DB applications. Next, you learned about some best practices to prevent these issues.
However, this article only scratches the surface of what Cosmos DB partitioning has to offer. Continue exploring the intricacies of Cosmos DB to learn more about its unique capabilities.
Site24x7 tracks critical Cosmos DB metrics such as provisioned throughput (RU/s), storage consumption, and throttled requests, helping you identify hot partitions and unbalanced workloads.
Yes, you can configure custom thresholds in Site24x7 to receive instant alerts when your Cosmos DB partitions experience high request unit consumption or storage limits, preventing performance bottlenecks.
Site24x7 monitors the latency and availability of your Cosmos DB instances, ensuring that your queries execute efficiently and highlighting potential issues related to poor partition key selection.