Analyze and optimize your PostgreSQL server with our PostgreSQL plugin integration.
Choosing the right database management system (DBMS) is one of the first major decisions of every new software project. MySQL and PostgreSQL are established options with great functionality support and scalability. They’re used by tech giants like Facebook and Instagram, who serve millions of users globally.
At the same time, there are significant differences between MySQL and PostgreSQL. In this article, we’ll explore these differences and learn how to make an informed choice.
A database management system (DBMS) is a set of software that allows users to manipulate or retrieve data stored in a database. With a DBMS, users can also change data structure or create functions for easier data manipulation.
An instance refers to the current state of the database at a particular time. This includes values stored in the database, the tables existing in it, and the relationships between tables.
Replication is the ability to copy data from a primary database to a secondary database so that the latter can serve as the former’s backup, when needed. The primary and secondary database will be synchronized regularly using cron jobs, or automatically after every update in the database to ensure the secondary database is up to date with the data state in the primary database.
A partition in the database is one part of a large table that has been cloned to boost performance during data queries from the database. Partitioning is supposed to occur only in a single database instance.
A shard is similar to a partition, as it’s also a cloned part of a large table. The difference is that through its mechanism, sharding can take place in multiple database instances even in multiple computers in different regions.
PostgreSQL and MySQL are database management systems that offer numerous functionalities to resolve a wide range of problems. The below technical comparison should help you understand how they differ and which of the two is the better fit for your project.
Differences between PostgreSQL and MySQL
| Items | PostgreSQL | MySQL |
|---|---|---|
| DBMS Type | Object-based relational database | Relational database |
| Data Types | Integers, text, booleans, and customer-defined data types | Only supports certain data types, namely numeric, date and time, string (character and byte), spatial types, and JSON |
| Storage Engine | Only zheap | InnoDB, MyISAM, Memory, CSV, Archive, and Blackhole |
| Schema | Databases can contain different schemas | Schema and database are synonymous |
| Tables | Supports inheritance for tables | Does not support inheritance |
| Languages | SQL, PL/pgSQL, and C | Only SQL |
| Customer operators | Supported | Not supported |
| Foreign tables | Supported | Not supported |
| Rules | Supported | Not supported |
PostgreSQL and MySQL both
PostgreSQL is an object-based relational database, while MySQL is a relational database. With PostgreSQL, users have support for objects, classes, and inheritance, just like in object-oriented programming languages.
PostgreSQL supports standard data types such as integers, text, booleans and customer-defined data types.
MySQL only supports certain data types, namely numeric, date and time, string (character and byte), and spatial types, and JSON.
PostgreSQL only supports a storage engine called zheap.
With MySQL, we can have multiple storage engines to choose from. The default storage engine of MySQL is InnoDB. MyISAM, Memory, CSV, Archive, and Blackhole are also supported.
In PostgreSQL, each database can contain different schemas. A public schema will be automatically created when we create a new database in PostgreSQL. In cases where there are more than 100 tables in the database, creating several different schemas for specific business requirements can keep us from getting overwhelmed by the sheer number of tables.
In MySQL, schema and database are similar.
Tables in PostgreSQL are inheritable and whenever we create a new table, an accompanying custom data type is created as well.
MySQL does not support inheritance for tables nor custom data types for them.
Views allow users to abstract multiple tables as a single table so we can easily query the exact data we want from several tables. MySQL and PostgreSQL let users update the underlying data from the current view.
Extensions support users to package functions, tables, data variables, and data structures into a single unit, which we can then plug to another database instance or remove as a whole. Both PostgreSQL and MySQL support using extensions for their databases.
MySQL and PostgreSQL support creating custom functions (alongside built-in ones) to perform calculations and data manipulation on multiple tables.
Multi-language support provides users the flexibility to define custom functions. By default, PostgreSQL supports three languages: SQL, PL/pgSQL, and C. For other languages, such as Python, Perl, or Javascript, we need to install the relevant extension in the PostgreSQL database. Meanwhile, MySQL only offers SQL for creating functions.
Operators are syntax for arithmetic operations and for comparison or logical operations. MySQL does not support creating custom operators but PostgreSQL does. Custom operators are helpful when working with custom data types.
Foreign tables are virtual tables that can link to other data sources such as CSV files or a NoSQL database like Redis or MongoDB. PostgreSQL supports foreign tables for convenient integration with other existing data formats, while MySQL does not.
The RDMS catalog stores information about the database system, such as its tables, relationships among the tables, and its metadata in general. Both MySQL and PostgreSQL support catalogs.
A sequence is a list of integers that can be generated using specific commands defined by RDMS. We can limit the number of integers in the sequence by its minimum and maximum numbers. This feature is supported both in PostgreSQL and MySQL.
Rules are used to define further actions to be performed after a specific operation is applied for a particular table. A rule is different from a trigger.Triggers are called after any one row is updated but rules can be called only once after multiple rows are updated. PostgreSQL supports rules, whereas MySQL does not.
Both MySQL and PostgreSQL support triggers, which are—as mentioned above—used to call for action after a row is updated.
Full text search allows users to match the entire word in search results instead of matching a specific pattern. Both PostgreSQL and MySQL support full text search.
When working with data, it is convenient to have a feature that supports converting it from one data type to another. Both MySQL and PostgreSQL offer this feature.
Both databases are designed to be scalable, so they’re both a good fit for enterprise projects with high volumes of data. However, suppose a project needs an efficient way to store transactional data (for example, banking projects) or contains custom object data types instead of standard data types only. In this case, PostgreSQL is the more appropriate choice.
On the other hand, MySQL will be more suitable for the following scenarios:
We have covered the differences between PostgreSQL and MySQL to get a close technical comparison and see how they fit software use cases. Now let’s take a look at the pros and cons of each.
PostgreSQL provides numerous features support for data storage and data manipulation but also has some drawbacks.
Pros:
Pros:
MySQL is known for its scaling performance and can be lightweight for small applications. However, the database still has some limitations, such as its narrow data type support.
Advantages of MySQL
Drawbacks of MySQL
The easiest way to understand how MySQL and PostgreSQL are used in the production environment is to see how a giant like Meta uses these two databases to handle huge workloads for Facebook and Instagram while maintaining the ability to scale up from time to time.
Facebook uses MySQL to manage petabytes of data generated by their customers. The reason it adopted MySQL for this task is that it is well supported for automation and allows small teams to handle thousands of database servers.
In Facebook, MySQL instances have a lifecycle. An instance can be in different states, such as production, spare, spare allocated, spare de-allocated, reimage, or drained.
Being in the production state means that the instance is currently running and serving customers. In the spare state, the instance is in the pool and can be used any time. Spare allocated, spare de-allocated, and reimage are transitional states in the database maintenance process. The drained state is when a database analyst investigates the database instance to address existing product issues or any other technical problems.
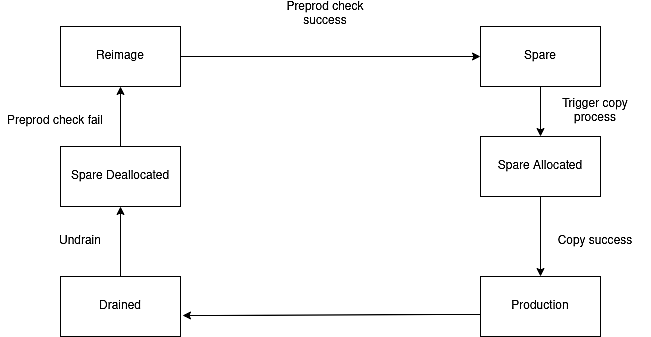 Fig. 1 : The lifecycle of MySQL instances
Fig. 1 : The lifecycle of MySQL instances
Service discovery is significant , especially for organizations like Facebook that have millions (or billions) of users and for whom downtime of mere minutes can lead to substantial financial losses. Service discovery helps handle catastrophic problems by elegantly replacing the problematic database instance with a new one ready to handle production workloads.
Service discovery at Facebook has a hash table storing the shard ID, replicaset, master, and slave of database instances. Service discovery will be aware of any problems with these instances and will quickly bring up another instance to replace them. After this update, the hash table will be updated with new values.
| Shard ID | ReplicaSet | Master | Slave |
|---|---|---|---|
| 0–99 | ReplicaSet 1 | db1.ms:3306 | db1.slav:3306 |
| 100–199 | ReplicaSet 2 | db2.ms:3306 | db2.slav:3306 |
| 200–299 | ReplicaSet 3 | db3.ms:3306 | db3.slav:3306 |
Data migration is notorious for the number of pain points facing software engineers as they deploy breaking changes to the production environment. Without the proper tools and techniques, software products might experience serious downtime. We’ll now look at how Facebook handles migration for MySQL instances.
This is the first step in a data migration task. It’s also needed for moving data from one place to another, balancing database utilization, or when dealing with broken database instances.
MPS Copy
MPS Copy is a tool developed at Facebook to manage the process of cloning instances. The stages in the cloning process that MPS Copy covers are:
Online migration (OLM) for shard helps move data around and is particularly useful when the database instance grows beyond the host level limit and needs to move to another host. The key concept of OLM is to move the data from a shard into another instance via local migration, then register the new shard address into the service discovery hash table.
Implementing proper load balancing execution for MySQL helps optimize system resources.
Let’s say there are four data instances accounting for 1TB of workload. Instance 1 is 400GB; instance 2 is 200GB’ instance 3 is 100GB, and instance 4 is 200GB. There are four hosts available for storing these instances, with the capacity of each host being 500GB.
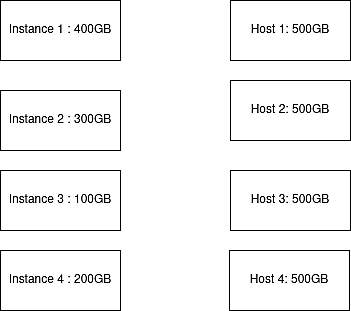 Fig. 2: Demonstration of instances and hosts before allocation
Fig. 2: Demonstration of instances and hosts before allocation
The first instance will be placed in host 1. Since host 1 does not have the needed capacity for instance 2 after putting instance 1 to host 1, instance 2 will be sent to host 2, as will instance 3. Now host 2 only has a capacity of 100GB left—not enough for instance 4. Instance 4 will then be moved to host 3.
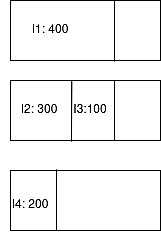 Fig. 3: Demonstration of poor stacking
Fig. 3: Demonstration of poor stacking
We now use three hosts for storing these four instances—but there is a better way to store them to utilize system resources.
Instead of storing instance 4 to host 3, we can store instance 3 to host 1 and instance 3 to host 2. With this approach, it only takes two hosts to store the data instances.
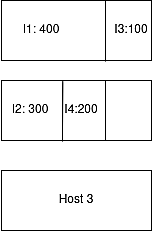 Fig. 4: Demonstration of proper stacking
Fig. 4: Demonstration of proper stacking
The key to proper stacking is that before assigning the instance to the host, we must check for the best spot possible for the instance to be put in.
For a slightly different take on the above case, let’s say time database instance 2 will be 200G and instance 3 will be 200GB.
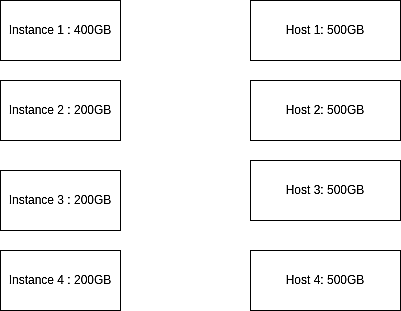 Fig 5: Demonstration of instances and hosts before allocation
Fig 5: Demonstration of instances and hosts before allocation
Here instance 1 will go to host 1; instance 2 and instance 3 will go to host 2. Instance 4 then cannot go to host 1 or 2 since they don’t have enough capacity, and it will be placed in host 3 instead. In this case, we’ve wasted host 3 to handle only 200GB of data.
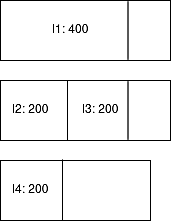 Fig. 6 : Demonstration of poor shaping
Fig. 6 : Demonstration of poor shaping
The solution for optimizing host capacity here is to split the workload.
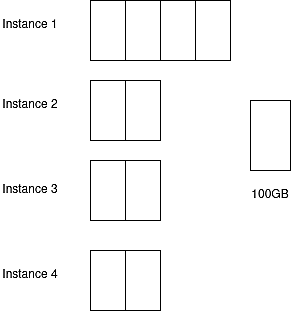 Fig. 7: Demonstration of splitting workload in database instance
Fig. 7: Demonstration of splitting workload in database instance
Then we can move a part of instance 4 to instance 2.
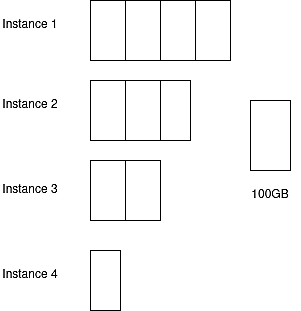 Fig. 8: Applying proper shaping resolves the problem
Fig. 8: Applying proper shaping resolves the problem
The problem we had with poor shaping is now resolved, and we only have the stacking issue left—and we already discussed the solution in the previous section.
Instagram uses PostgreSQL and a few other database management systems, such as Apache Cassandra or caching solution databases like Redis. Let’s look at how Instagram uses PostgreSQL and how they scale PostgreSQL instances to handle enormous daily workloads.
The first thing Instagram tried to handle more workload from users in PostgreSQL database instances was sharding their databases. They had considered using other solutions, such as NoSQL databases but they eventually realized that sharding their data instances into smaller buckets would work best. This solution fits a workload of 90 likes per second, but when it increases to 10,000 likes per second, sharding alone won’t suffice.
Before applying partial indexes, querying tags from a minority of rows at PostgreSQL databases took 215 ms.
EXPLAIN ANALYZE SELECT id from public.tags WHERE name LIKE 'snow%' ORDER BY media_count DESC LIMIT 10;
QUERY PLAN
---------
Limit (cost=1780.73..1780.75 rows=10 width=32) (actual time=215.211..215.228 rows=10 loops=1)
-> Sort (cost=1780.73..1819.36 rows=15455 width=32) (actual time=215.209..215.215 rows=10 loops=1)
Sort Key: media_count
Sort Method: top-N heapsort Memory: 25kB
-> Index Scan using tags_search on tags_tag
(cost=0.00..1446.75 rows=15455 width=32) (actual time=0.020..162.708 rows=64572 loops=1)
Index Cond: (((name)::text ~>=~ 'snow'::text) AND ((name)::text ~<~ 'snox'::text))
Filter: ((name)::text ~~ 'snow%'::text)
Total runtime: 215.275 ms
(8 rows)
In this case, PostgreSQL had to sort through almost 15,000 rows to query the correct result. After applying a partial index, the time needed went down to only 3ms.
CREATE INDEX CONCURRENTLY on tags (name text_pattern_ops) WHERE media_count >= 100
EXPLAIN ANALYZE SELECT * from tags WHERE name LIKE 'snow%' AND media_count >= 100 ORDER BY media_count DESC LIMIT 10;
QUERY PLAN
Limit (cost=224.73..224.75 rows=10 width=32) (actual time=3.088..3.105 rows=10 loops=1)
-> Sort (cost=224.73..225.15 rows=169 width=32) (actual time=3.086..3.090 rows=10 loops=1)
Sort Key: media_count
Sort Method: top-N heapsort Memory: 25kB
-> Index Scan using tags_tag_name_idx on tags_tag (cost=0.00..221.07 rows=169 width=32) (actual time=0.021..2.360 rows=924 loops=1)
Index Cond: (((name)::text ~>=~ 'snow'::text) AND ((name)::text ~<~ 'snox'::text))
Filter: ((name)::text ~~ 'snow%'::text)
Total runtime: 3.137 ms
(8 rows)
This time PostgreSQL only needed to look at 169 rows. This is why it’s way faster with a partial index applied than without.
Functional indexes like indexing strings can prove helpful when scaling PostgreSQL database instances to increased workloads. For example, with based64 tokens that are very long, creating indexers for these strings isn’t efficient, and we’d just end up with duplicate data. By using function indexing, the indexing size is only a tenth of the full indexing way.
CREATE INDEX CONCURRENTLY on tokens (substr(token), 0, 8)
PostgreSQL data tables can be fragmented on disks due to being implemented using a multiversion concurrency model. To deal with the problem, Instagram used pg_reorg to restructure the data table in five steps:
Instagram used WAL-E, a tool created by Heroku for continuous archiving PostgreSQL log files. This combination of backups and using WAL-E has allowedInstagram to quickly deploy a new replica for its PostgreSQL database or switch to an existing secondary node from the primary one.
Instagram has used psycopg2, a python driver for PostgreSQL, in the Django application. With autocommit mode enabled, psycopg2 won’t call BEGIN/COMMIT for every query but will instead have its own single transaction.
connection.autocommit = True
This results in lower system CPU usage and fewer requests between servers and databases.
Finding the one database that aligns with a project’s specific needs is not an easy feat—it requires a thorough understanding of work requirements and the technological aspects of each database considered.
In this article, we covered the benefits and drawbacks of MySQL and PostgreSQL and examined how two organizations under the Meta umbrella selected each to match their unique business needs and scaling requirements for growth. These examples will hopefully prove helpful while choosing a database for your next software project.
Yes, Site24x7 provides deep performance monitoring for both MySQL and PostgreSQL databases, tracking key metrics like query execution time, connection stats, and buffer usage.
Site24x7 captures slow queries and analyzes database locks, helping you pinpoint inefficient queries or resource bottlenecks in both MySQL and PostgreSQL environments.
Yes, Site24x7 supports monitoring for cloud-hosted databases like Amazon RDS for MySQL and PostgreSQL, Azure Database, and Google Cloud SQL.
